

Bridging Backend and Data Engineering: Communicating Through Events
Building a Unified System: Event-Driven Approach to Backend and Data Engineering Communication.

Introduction
In the rapidly evolving landscape of software development, the need for seamless communication between backend services and data engineering pipelines has become paramount.
Traditional methods, such as REST APIs for backend services and batch processing for data pipelines, often fall short in providing the real-time, scalable, and flexible solutions required by modern applications.
This is where event-driven architecture (EDA) comes into play, offering a robust framework for integrating these disparate systems through asynchronous event communication.
However, if you did not build those systems with an event-driven architecture in mind from day one, what can you do?
For small teams, it can also be daunting and time-consuming to think about, implement, and maintain such systems.
A hybrid solution
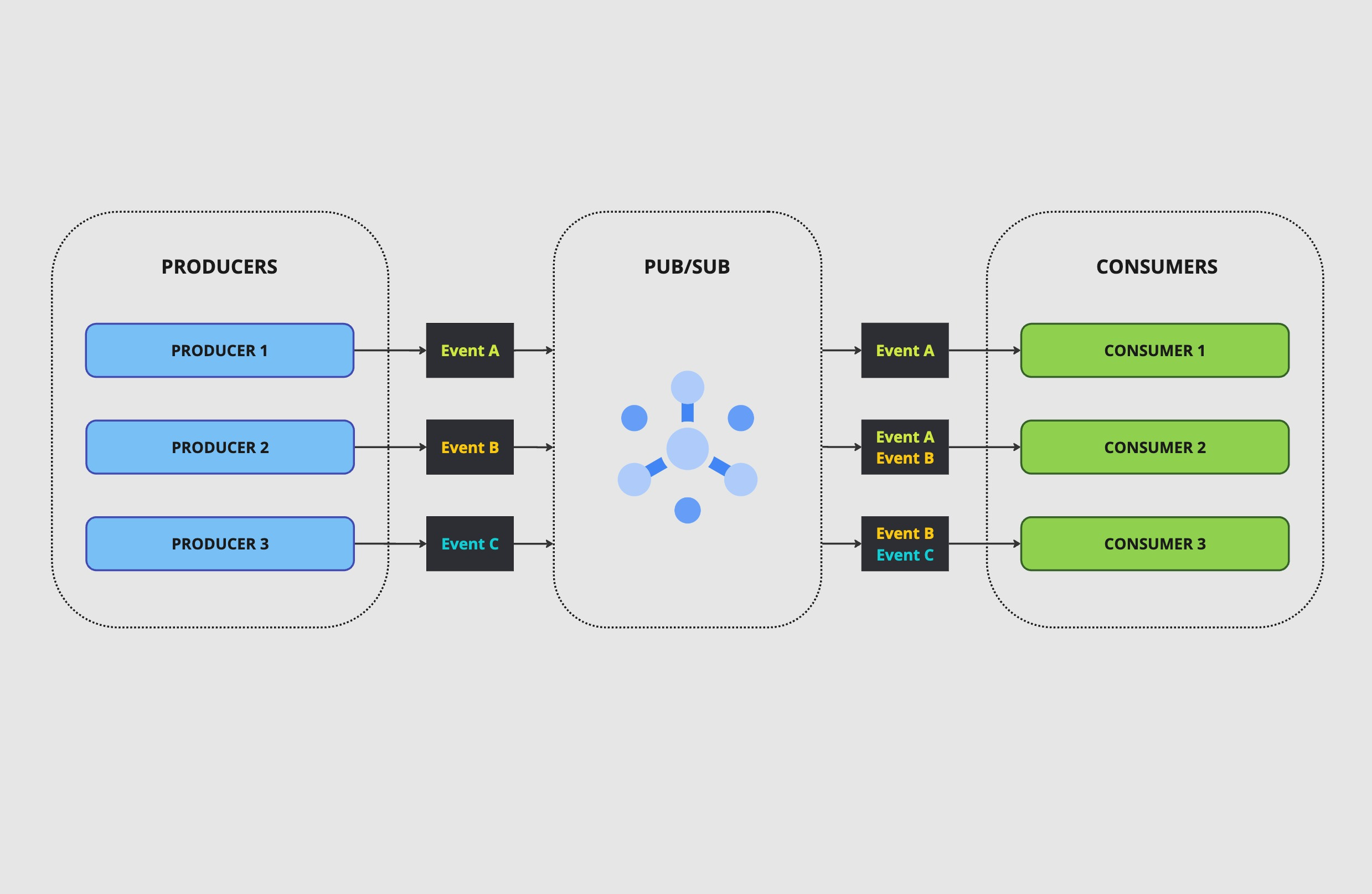
One easy way to reach some kind of event-driven platform without going all the way in is simply to set up a Pub/Sub system (e.g., GCP Pub/Sub, Amazon SQS, Redis Pub/Sub, RabbitMQ, etc.).
This involves setting up producers that send messages through a topic and consumers that read them via a subscription.
From there, the hard part is defining a standard way of expressing events that come through your system, whether they are ETL pipeline events or backend service events.
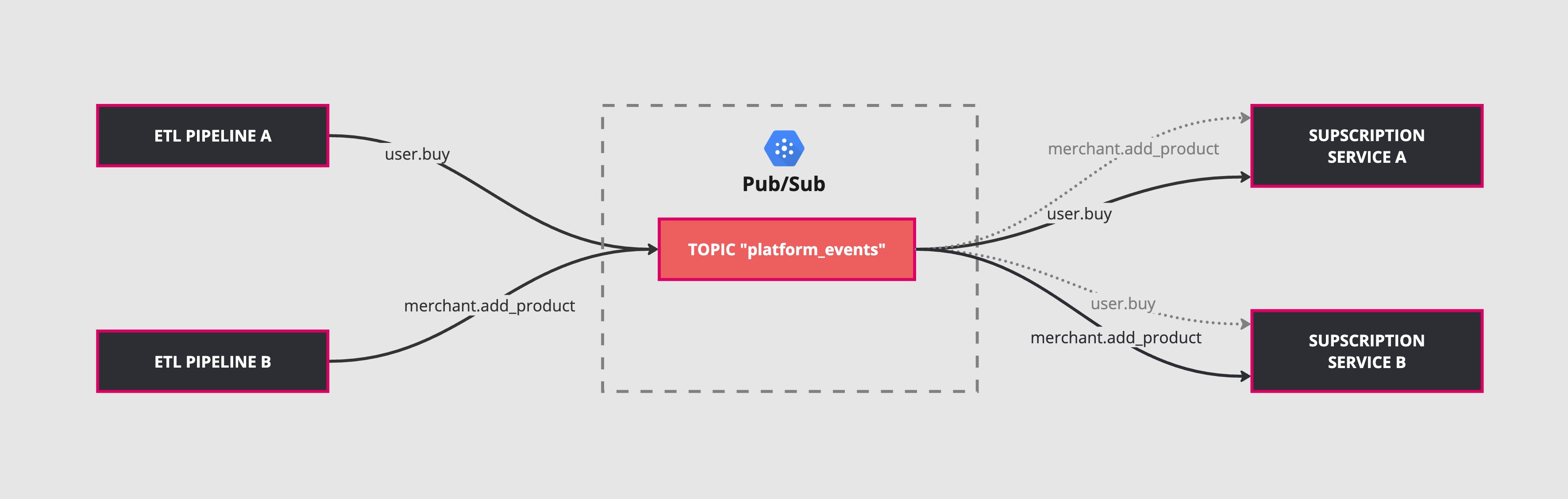
You could define one topic to start with, let’s call it “platform_events”, where any service would broadcast its events in a standardized format.
Let’s take an e-commerce example with buyers, orders, products, and merchants that is deployed on GCP and uses GCP Pub/Sub.
You gather your backend and data engineering teams, and all of them agree on adding optional attributes (merchant_id, buyer_id, event_name), and a JSON-marshalled payload.
From there, any service can subscribe to that unique topic to receive a copy of those events. Each service can have its own router in place that quickly reads the event name to decide whether to skip or consume it.
Notice that subscriptions decide which events to process and which simply to ignore.
All events?
Yes, in the context of a small/medium team and as a first version of this event-driven architecture, it is fine to receive a copy of all events from a single topic.
Each service, API, or daemon can decide to subscribe and consume or not consume different types of events. For instance, your API might be interested in knowing when an event of the type “user.buy” or “user.refund” happens but doesn’t care about “merchant.add_product” or “merchant.edit_product”.
It’s up to your project to decide what’s good to keep and what is good to skip. By skipping, you still need to acknowledge your event, but you simply do nothing else.
Strategy
From there, it makes sense to add as many events as you can, giving other teams a flourishing list of events they can use to improve their own services.
As long as they are documented properly, everyone can add new events that make sense.
We tend to create events only if it’s concerted, though it doesn’t have to be, the same way we all tend to write a minimum amount of logs and add more when there is a bug or something we don’t understand happening.
It doesn’t really cost more to send events that won’t be read by anyone; they might be useful later.
It becomes even more valuable because you could write a simple daemon that subscribes to this platform topic and writes down all these events into a database, as logs or metrics directly.
It is also a good way to trace what happens in your API flows and pipelines, and since you have metadata, you can connect the dots together.
Metadata / Attributes
Event metadata are key/values that should make it easy to identify the overall context of your events.
It is sometimes hard to define what’s the context and what’s the payload. For example, in our e-commerce, it makes sense to send user_id, merchant_id, order_id.
However, the product ids from the order are not necessary, this is something you will get by requesting the order from your DB.
Event {
Attributes: {
"type": "user.buy",
"user_id": 1,
"merchant_id": 2,
"order_id": 3
}
Payload: "json_string.."
}Event type
Since the strategy is to send as many descriptive events as possible, the event “type” format is important, usually things follow a kind of path or namespace.
In our e-commerce examples, let’s keep it to 2 levels the Subject and the Action like “user” (Subject) and “buy” (Action).
You can then imagine different event types for user, the most important thing is that it’s easy to read and understand:
user.buy
user.refund
user.complaint
user.follow
user.unfollow
Conclusion
In order to bridge backend and data engineering asynchronous communication via an event driven approach, there is no need to redo your entire infrastructure.
With a Pub/Sub system and standardized events, services can selectively subscribe to relevant messages for asynchronous communication.
Once you write some common code or library that every team can import in their projects it becomes an efficient plug and play system.