

Introductioon
Database Proxies can enhance performance and security in complex, high-traffic distributed systems built with Microservices.

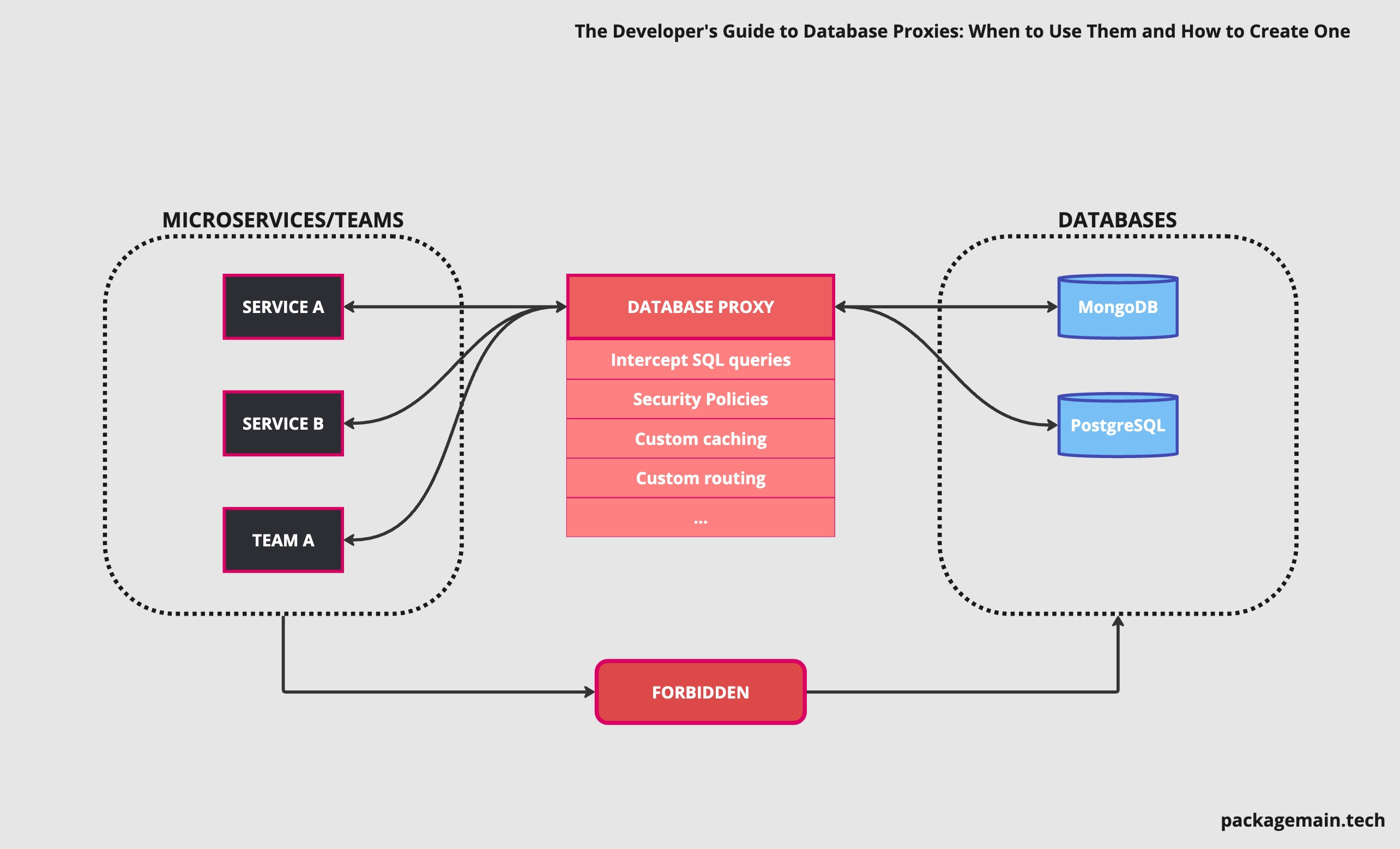
Imagine a complex distributed system that relies heavily on data, where each microservice or a team connects to a database individually (it can be a shared database or specific/isolated ones). Such a complex platform requires things like centralized monitoring, query validations, alerting, custom sharding, and better security, you name it. While you can get a lot of that from your database server, implementing a database proxy may be a better approach (if you’re ready to invest in it).
The main advantage of using a database proxy is that it isolates the database topology from the application layer, so that developers don’t need to know about clusters, nodes and internals of the Data layer (to some extent obviously).
Database Proxy Use Cases
Let’s dive into the various ways database proxies can empower your development teams, enhance security, and optimize database performance.
Intercept SQL queries from applications and dynamically route them to the correct database/table (for example custom sharding). Figma is doing exactly that with their internal Postgres proxy.
Parse/Analyze/Validate SQL queries from developers and enrich the response with additional information. Could be useful to tell applications which tables are going to be deprecated.
Scalability and schema changes without impacting applications. Platform/Database teams can independently change the schema without rewriting hundreds of microservices. The ability to transparently add or remove nodes in the database cluster without having to reconfigure or restart an application.
Enforce security policies and perform authentication and authorization checks to ensure that only authorized clients can access the database. Direct access to a database can be also forbidden.
Improve the performance of database communication by centrally managing the pool of connections, utilizing cache technics, etc.
Centralized observability. Get notified when an application is using a deprecated table, and much more.
When to use a Database Proxy
Not all systems need a database proxy, especially early on. Here is the general guideline for when it might become necessary:
You have multiple development teams split by different disciplines: for example multiple Backend Teams, Data Engineering team.
You have a Platform/Database team to be an owner of that. Though other teams can own it as well.
Your system is distributed, and you maintain many microservices and many databases.
Your system is data-heavy.
You need better Security and Observability.
Cost of having a Database Proxy
Using a Database Proxy does come at a cost:
A database proxy is a new element in the infrastructure with its own complexity.
Could be a single point of failure, so has to be very stable and battle-tested.
Additional network latency.
Types of Database Proxies
There are a few ways how you can deploy a database proxy:
Custom proxy service (below I’ll provide a simple example in Go)
Managed Cloud solutions like Amazon RDS Proxy
Sidecars like Cyral
Commercial and open-source products like ProxySQL, or dbpack
Writing a custom Database Proxy Service in Go
Now, we are going to implement our own MySQL proxy using Go. Keep in mind that this is only an experiment to explain the idea.
Our proxy will solve a very simple use case: intercept SQL query and rewrite table name if it matches a pattern.
-- Application-generated query
SELECT * FROM orders_v1;
-- Rewritten query
SELECT * FROM orders_v2;The implementation is divided into two parts:
Basic proxy to route queries from client to MySQL server.
SQL parser with some logic to manipulate the query before it’s sent.
You can see the full source in this Github repository.
TCP proxy from client to MySQL server
Our TCP Proxy is implemented in a very naive approach, and is definitely not production-ready, but is enough to demonstrate how TCP transport works:
Create a proxy TCP server
Accept the connection
Create TCP connection to MySQL
Proxy byte stream from the client to the MySQL Server, and back by using pipes
main.go
package main
import (
"fmt"
"io"
"log"
"net"
"os"
)
func main() {
// proxy listens on port 3307
proxy, err := net.Listen("tcp", ":3307")
if err != nil {
log.Fatalf("failed to start proxy: %s", err.Error())
}
for {
conn, err := proxy.Accept()
log.Printf("new connection: %s", conn.RemoteAddr())
if err != nil {
log.Fatalf("failed to accept connection: %s", err.Error())
}
go transport(conn)
}
}
func transport(conn net.Conn) {
defer conn.Close()
mysqlAddr := fmt.Sprintf("%s:%s", os.Getenv("MYSQL_HOST"), os.Getenv("MYSQL_PORT"))
mysqlConn, err := net.Dial("tcp", mysqlAddr)
if err != nil {
log.Printf("failed to connect to mysql: %s", err.Error())
return
}
readChan := make(chan int64)
writeChan := make(chan int64)
var readBytes, writeBytes int64
// from proxy to mysql
go pipe(mysqlConn, conn, true)
// from mysql to proxy
go pipe(conn, mysqlConn, false)
readBytes = <-readChan
writeBytes = <-writeChan
log.Printf("connection closed. read bytes: %d, write bytes: %d", readBytes, writeBytes)
}
func pipe(dst, src net.Conn, send bool) {
if send {
intercept(src, dst)
}
_, err := io.Copy(dst, src)
if err != nil {
log.Printf("connection error: %s", err.Error())
}
}
func intercept(src, dst net.Conn) {
buffer := make([]byte, 4096)
for {
n, _ := src.Read(buffer)
dst.Write(buffer[0:n])
}
}Functions explained:
transport - handles TCP connection and pipes bytes in two directions.
pipe - pipes bytes, if it’s proxy → mysql, it also calls intercept to process the query.
intercept - we will implement it later to parse the query.
Dockerfile
FROM golang:1.22 as builder
WORKDIR /
COPY . .
RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -o proxy main.go
FROM alpine:latest
COPY --from=builder /proxy .
EXPOSE 3307
CMD ["./proxy"]docker-compose.yaml
services:
proxy:
restart: always
build:
context: .
ports:
- 3307:3307
environment:
- MYSQL_HOST=mysql
- MYSQL_PORT=3306
links:
- mysql
mysql:
restart: always
image: mysql:5.7
platform: linux/amd64
ports:
- 3306:3306
environment:
- MYSQL_ROOT_PASSWORD=root
command: --init-file /data/application/init.sql
volumes:
- ./init.sql:/data/application/init.sqlinit.sql
CREATE DATABASE IF NOT EXISTS packagemain;
CREATE TABLE IF NOT EXISTS packagemain.orders_v2 (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL
) ENGINE=InnoDB;
INSERT INTO packagemain.orders_v2 (name) VALUES ('order1');Note: we don’t have orders_v1 table in our database.
SQL Parsing
Our function intercept can already get a bytes packet. It’s good to understand how MySQL packet is structured. I won’t get into details, but you can read it here.
In our intercept function we do the following:
Look for a COM_QUERY client command which has a numeric code 3.
Get the raw query.
Do very basic table rename.
There is a great package sqlparser from Youtube’s Vitess project, which we can use to parse SQL queries. However, for simplicity of this demonstration, we’re going to use string matching and replacing.
main.go
const COM_QUERY = byte(0x03)
func intercept(src, dst net.Conn) {
buffer := make([]byte, 4096)
for {
n, _ := src.Read(buffer)
if n > 5 {
switch buffer[4] {
case COM_QUERY:
clientQuery := string(buffer[5:n])
newQuery := rewriteQuery(clientQuery)
fmt.Printf("client query: %s\n", clientQuery)
fmt.Printf("server query: %s\n", newQuery)
writeModifiedPacket(dst, buffer[:5], newQuery)
continue
}
}
dst.Write(buffer[0:n])
}
}
func rewriteQuery(query string) string {
return strings.NewReplacer("from orders_v1", "from orders_v2").Replace(strings.ToLower(query))
}
func writeModifiedPacket(dst net.Conn, header []byte, query string) {
newBuffer := make([]byte, 5+len(query))
copy(newBuffer, header)
copy(newBuffer[5:], []byte(query))
dst.Write(newBuffer)
}Running the proxy and connecting to it
Here we connect to our Proxy which is running on port 3307, not a MySQL server itself (port 3306). And as you can see we can use regular MySQL client, which simplifies the use of this proxy.
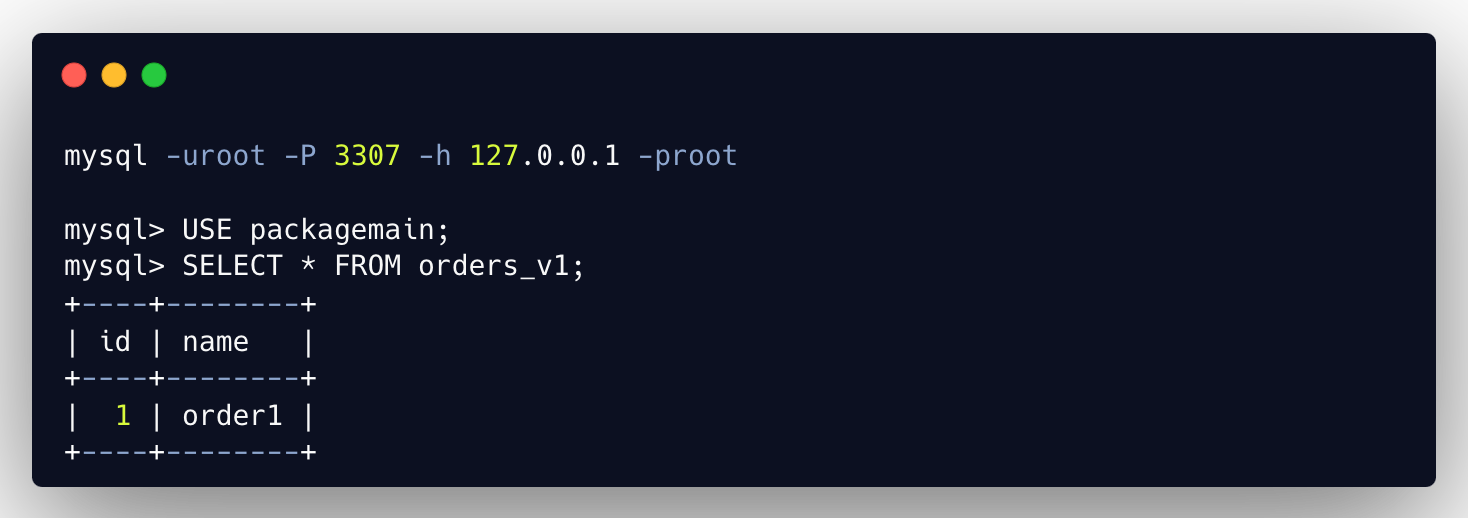
Which means orders_v1 table got rerouted to orders_v2. Proxy logs:
client query: select * from orders_v1;
server query: select * from orders_v2;Conclusion
In conclusion, a database proxy offers a powerful layer of abstraction between your applications and the underlying database(s). It streamlines development by isolating database complexity, empowers database teams with independent schema changes, and enhances security through centralized access control. While there are additional costs like infrastructure overhead and potential latency, for complex distributed systems with multiple teams and data-intensive needs, a database proxy can be a worthwhile investment.
nice article, thanks for sharing