

Unified Cache Keys: How Namespaced Keys Improve Service Interoperability
More than just random keys in a Redis.

Introduction
Developers tend to use cache to store a key / value pair, something that they need their program to remember for a period of time to avoid performing a bigger or slower operation to retrieve data again.
One important feature of caching, is that it shouldn’t be a point of failure. If your cache get flushed, your application should still be running without failing.
Often, cache keys should be expired, either by a mechanism that updates their value or simply by expiring after a period of time. A combination of both is great. That’s to ensure you are not seeing outdated data forever.
Cache keys are usually generated based on known values from the context surrounding the code. Like the URL path and parameters or a user id and it’s order id etc..
The problem
In order to get or invalidate the cached value, you need to recreate the same key that stored it. If you are in the same code path or code context, it’s totally fine, that’s the normal use case of cache.
What about events in your platform that requires to flush composite cache keys ? A composite cache key is a key that is relevant to more than 1 business entity.
Like a user’s dashboard configuration.
Now, in that context, if something changes on the dashboard OR on the user side, you might have to delete, expire or replace that cache key.
So if your code has the user already, you would need to go get the dashboard or vice versa in order to recreate that generated key and act on it.
Another use case would be, when you have multiple services, they might not have the full context like users service doesn’t know about dashboards and probably shouldn’t. Therefore it’s hard for it to expire composite cache keys.
Prerequisite
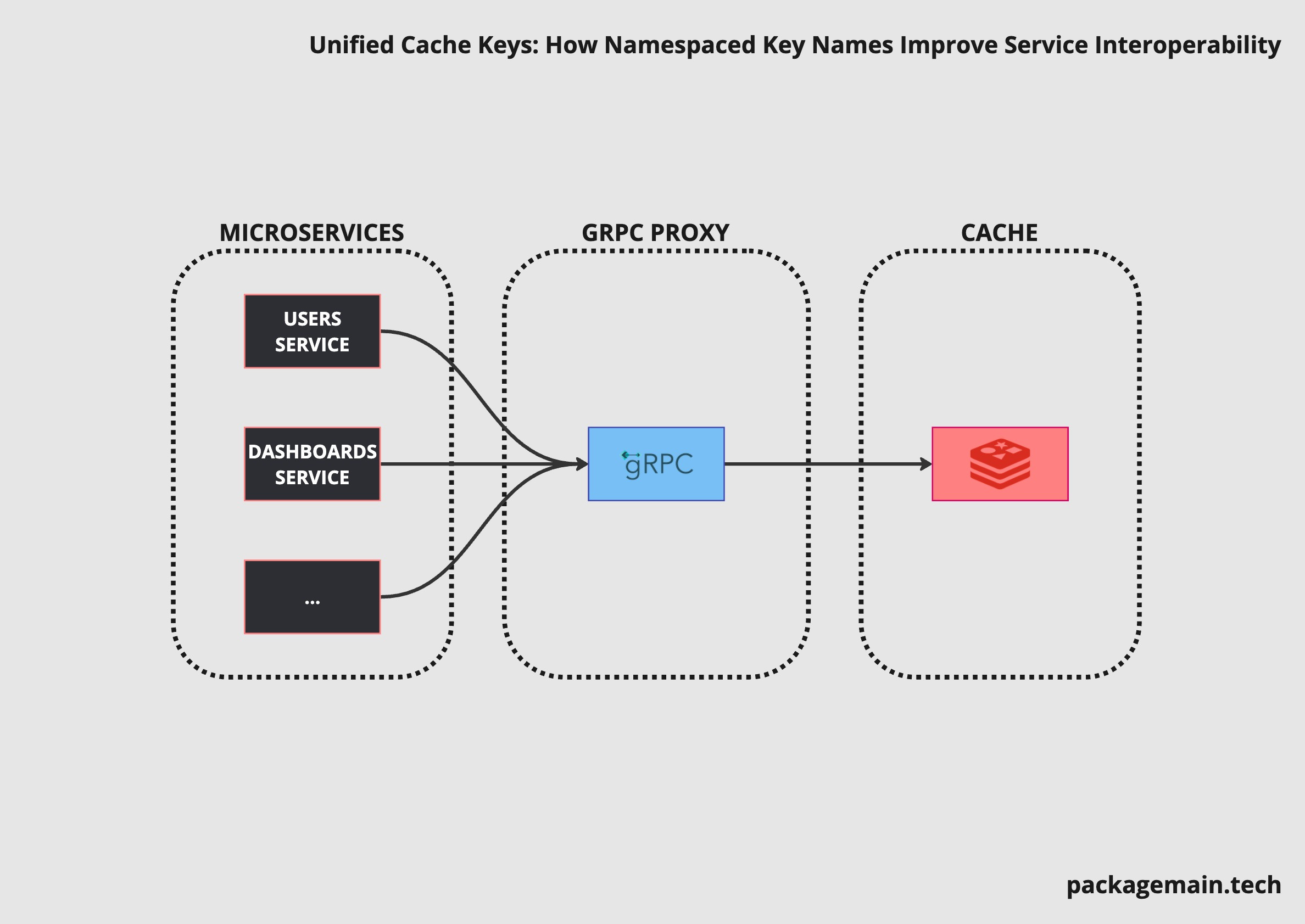
This article uses Redis as a cache key/value store, it uses wildcards. It also assumes you are willing to have a centralized cache service instead of Microservices with their own instance of cache.
Concept
Why not approach keys as Namespaces with Labels instead of a simple string generated via keywords and some metadata?
Similar to an URL like: packagemain.tech/posts/likes?orderby=date
Namespaces (or Paths)
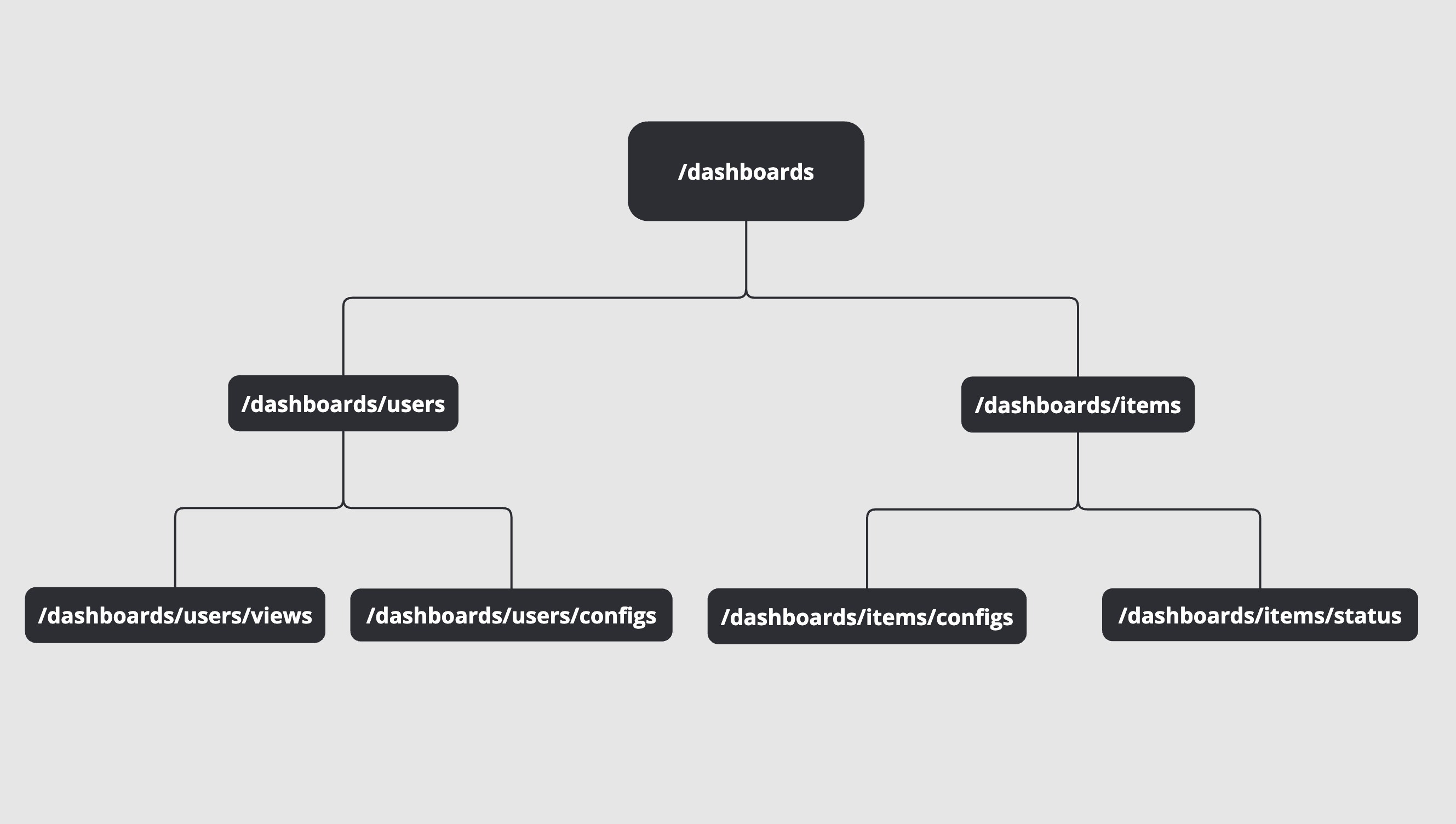
That way, it becomes a tree of keys incorporating business entities relationships.
For instance:
/dashboards/users
/dashboards/users/configurations
I use slash (/), you can use any other separator like dot (.) or two columns (::) whatever works for you, it just requires adapting the code to parse it later.
Notice how, I didn’t insert any actual metadata inside that string, we follow like URL paths parameters: /dashboards/{dashboard_id}/users/{user_id}/configurations
By using namespaces like a path, you can invalidate cache entries associated with specific business entities.
You can now deploy a new version of your dashboards and flush the entire cache that follows by asking your cache service to remove /dashboards/*
Everything under, if you build your cache keys with cohesion and logic will be flushed for every customer.
Labels
Labels tend to provide more fine grain capabilities. Labels are your context, the metadata you use when you generate your cache keys to be unique.
I would even encourage you to add more than what you used before, to give you more flexibility.
Example: dashboard_id=456:user_id=123
Whenever your customer removes dashboard 456, it’s easy to get all the keys that have that exact label and remove all of them.
Combined
Once you assemble both namespaces and labels, cache keys look like Path URLs now:
/dashboards/users/configurations?dashboard_id=456:user_id=123
Remove all dashboards related cache keys
/dashboards*
Remove all users’ dashboards configurations
/dashboards/users/configurations*
Remove user 123 keys
*user_id=123*
Remove user 123 and dashboard 456 composite keys
*dashboard_id=456:user_id=123*
Notice that, it’s important to sort the labels before generating the key so that the cache key is always the same, no matter in what order the labels go.
Improving Service Interoperability
As a team, it will be important to define cache keys not just for your project but also in line with other services running and using cache keys.
Creating this tree of business entities and relationship is now a shared effort, it will help every team to expire cache either based on a Path or on specific labels.
Therefore Paths will need to be documented somewhere for teams to refer to them.
Solution
Architecture
A good way of thinking of this would be a Redis database that is proxied by a gRPC service.
The gRPC service will receive requests to Get, Set or Delete.
Proto
Example of a proto file:
syntax = "proto3";
package cache_service;
service Cache {
rpc Set(SetRequest) returns (SetResponse) {}
rpc Get(GetRequest) returns (CacheEntry) {}
}
message CacheEntry {
string path = 1;
map<string, string> labels = 2;
bytes data = 3;
int64 expiration = 4;
}
message SetRequest {
CacheEntry entry = 1;
}
message SetResponse {
bool success = 1;
}
message GetRequest {
string path = 1;
map<string, string> labels = 2;
}Note: inside SetInput there is bytes data, the actual data you want to store in the cache, which also means you will have to encode somehow the object, map or whatever you want to store in there. Generally, people use JSON encoding here but you can use msgpack or anything else that let you decode it later.
Code
Constants
const (
LABEL_KEY_VALUE_SEPARATOR = "="
NAMESPACE_LABEL_SEPARATOR = "?"
LABEL_SEPARATOR = ":"
PATH_SEPARATOR = "/"
)Parsing
func parseLabels(key string) map[string]string {
labels := strings.Split(key, LABEL_SEPARATOR)
mapLabels := make(map[string]string, len(labels))
for _, label := range labels {
key, value := parseLabel(label)
if len(key) > 0 {
mapLabels[key] = value
}
}
return mapLabels
}
func parseLabel(label string) (string, string) {
s := strings.Split(label, LABEL_SEPARATOR)
return s[0], strings.Join(s[1:], LABEL_SEPARATOR)
}In the parseLabel function, we do something a bit strange, why not simply strings.Split ? Well maybe your separator is being used in the value of your label, therefore we simply make sure we split only the first colon (:) and rebuild the string behind just in case to avoid any alteration of the actual value.
Formatting
func FormatKey(path string, labels map[string]string) string {
return fmt.Sprintf("%s%s%s", formatPath(path), NAMESPACE_LABEL_SEPARATOR, formatLabels(labels))
}
func formatPath(path string) string {
if len(path) > 0 {
path = PATH_SEPARATOR + strings.TrimPrefix(path, PATH_SEPARATOR)
path = strings.TrimSuffix(path, PATH_SEPARATOR) + PATH_SEPARATOR
}
return path
}
func sortLabels(labels map[string]string) []string {
keyValues := make([]string{}, len(labels))
for key, val := range labels {
keyWithValues = append(keyWithValues, fmt.Sprintf("%s%s%s", key, LABEL_KEY_VALUE_SEPARATOR, val))
}
sort.Strings(keyWithValues)
return keyWithValues
}
func formatLabels(labels map[string]string) string {
keyValues := sortLabels(labels)
return strings.Join(keyValues, LABEL_SEPARATOR)
}Formatting Wildcards
func FormatPatternKey(path string, labels map[string]string) string {
return fmt.Sprintf("%s%s", formatPatternPath(path), formatPatternLabels(labels))
}
func formatPatternLabels(labels map[string]string) string {
keyValues := sortLabels(labels)
if len(keyValues) == 0 {
return ""
}
return fmt.Sprintf("%s*", strings.Join(keyValues, "*"))
}
func formatPatternPath(path string) string {
pattern := formatPath(path)
return pattern + "*"
}FormatPatternKey lets you provide both path and labels and generate a wildcard cache keys that let you search for all keys that match it.
Conclusion
All that is left to implement are the Redis client, gRPC server, Get, Set, Delete and a function to list keys from Redis so you can Delete via wildcards.